

BHP is very impressed with the geological outcome that was based on the best analytics available.
Stephen Busuttil
Manager Data, BHP





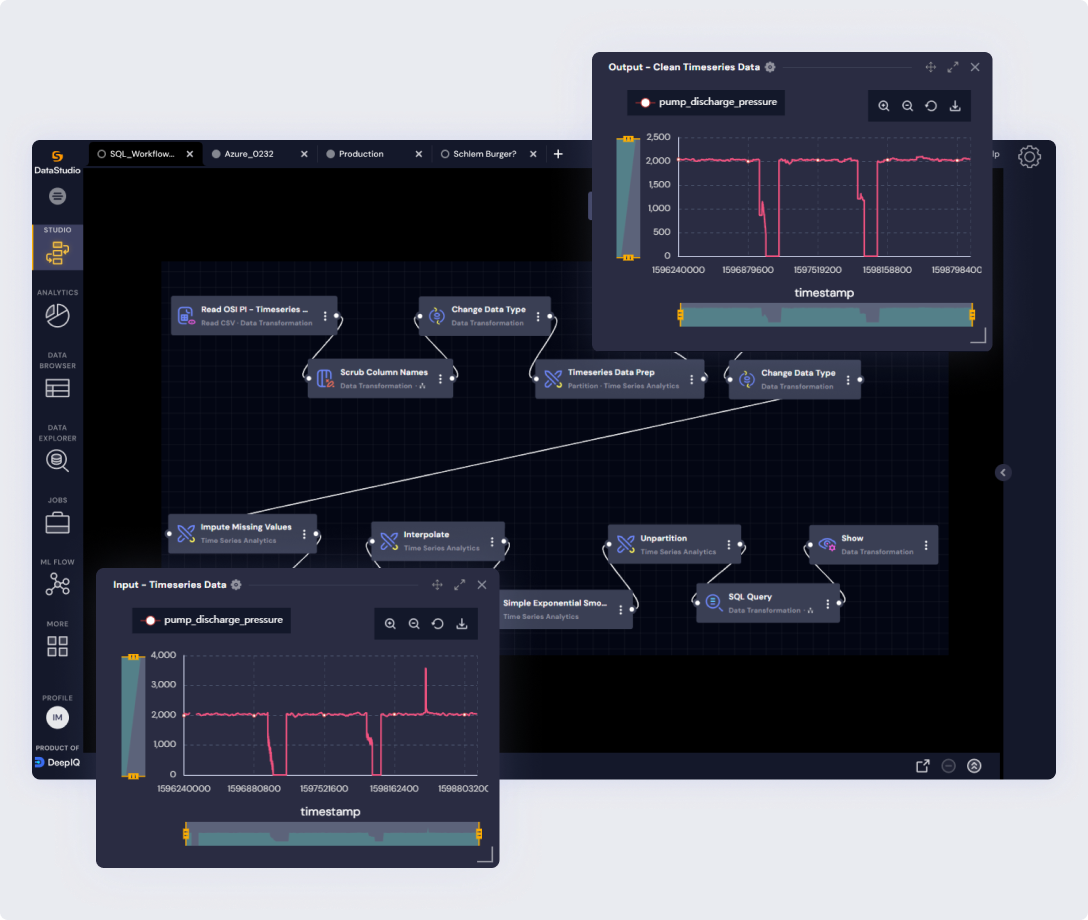
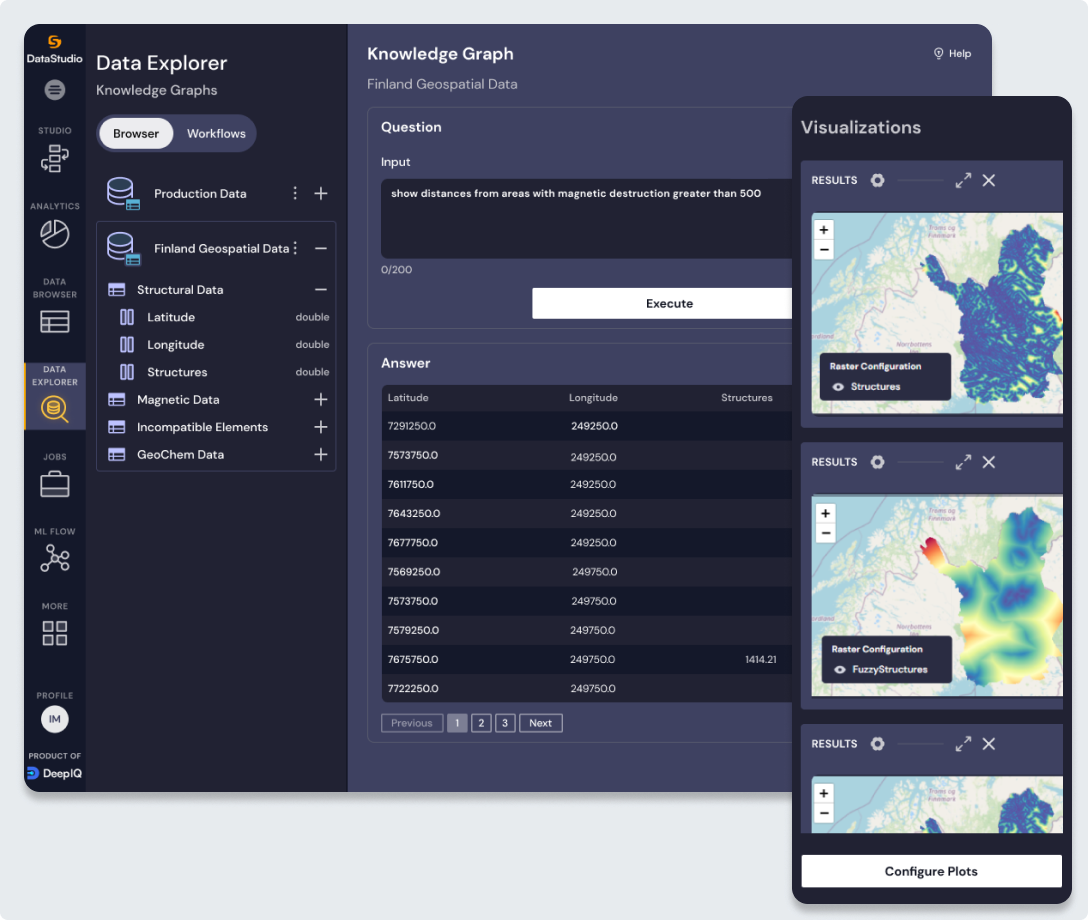





BHP is very impressed with the geological outcome that was based on the best analytics available.
Manager Data, BHP